
هذه العيون الآلية –
يمكن لنموذج الروبوت الآلي “الأول من نوعه” التعرف على القمامة وتنفيذ الإجراءات المعقدة.
تكبير / روبوت جوجل يتحكم فيه RT-2.
{kind=link}
جوجل
يوم الجمعة ، أعلنت Google DeepMind المحولات الروبوتية 2 (RT-2) ، أ “الأول من نوعه” نموذج الرؤية – اللغة – الإجراء (VLA) الذي يستخدم البيانات التي تم كشطها من الإنترنت لتمكين تحكم آلي أفضل من خلال أوامر لغة بسيطة. الهدف النهائي هو إنشاء روبوتات للأغراض العامة يمكنها التنقل في البيئات البشرية ، على غرار الروبوتات الخيالية مثل الجدار- E أو C-3PO.
عندما يريد الإنسان أن يتعلم مهمة ما ، فإننا غالبًا ما نقرأ ونلاحظ. بطريقة مماثلة ، تستخدم RT-2 نموذجًا لغويًا كبيرًا (التقنية الكامنة وراء الدردشة) تم تدريبه على النصوص والصور الموجودة على الإنترنت. يستخدم RT-2 هذه المعلومات للتعرف على الأنماط وتنفيذ الإجراءات حتى لو لم يتم تدريب الروبوت بشكل خاص على القيام بهذه المهام – وهو مفهوم يسمى التعميم.
على سبيل المثال ، تقول Google إن RT-2 يمكن أن يسمح للإنسان الآلي بالتعرف على القمامة ورميها بعيدًا دون أن يتم تدريبه بشكل خاص على القيام بذلك. يستخدم فهمه لماهية القمامة وكيف يتم التخلص منها عادة لتوجيه أفعالها. حتى أن RT-2 يرى عبوات الطعام المهملة أو قشور الموز على أنها قمامة ، على الرغم من الغموض المحتمل.
{kind=link}
تكبير / أمثلة على المهارات الروبوتية المعممة يمكن أن يؤديها RT-2 والتي لم تكن موجودة في بيانات الروبوتات. بدلاً من ذلك ، تعلمت عنها من قصاصات الويب.
جوجل
في مثال آخر ، اوقات نيويورك يروي أحد مهندسي Google الأمر ، “التقط الحيوان المنقرض” ، وقام الروبوت RT-2 بتحديد مكان واختيار ديناصور من بين مجموعة من ثلاثة تماثيل على طاولة.
هذه القدرة جديرة بالملاحظة لأن الروبوتات يتم تدريبها عادةً من عدد كبير من نقاط البيانات المكتسبة يدويًا ، مما يجعل هذه العملية صعبة بسبب الوقت والتكلفة العالية لتغطية كل سيناريو ممكن. ببساطة ، العالم الحقيقي عبارة عن فوضى ديناميكية ، مع تغيير المواقف وتكوينات الكائنات. يحتاج مساعد الروبوت العملي إلى أن يكون قادرًا على التكيف أثناء الطيران بطرق يستحيل برمجتها بشكل صريح ، وهنا يأتي دور RT-2.
أكثر مما تراه العين
مع RT-2 ، اعتمد Google DeepMind إستراتيجية تعمل على نقاط القوة في نماذج المحولات AI، المعروفة بقدرتها على تعميم المعلومات. يعتمد RT-2 على عمل سابق لمنظمة العفو الدولية في Google ، بما في ذلك نموذج لغة Pathways والصورة (PaLI-X) ونموذج لغة المسارات المجسد (PaLM-E). بالإضافة إلى ذلك ، تم تدريب RT-2 أيضًا على البيانات من الطراز السابق (RT-1) ، والتي تم جمعها على مدى 17 شهرًا في “بيئة مطبخ المكتب” بواسطة 13 روبوتًا.
تتضمن بنية RT-2 ضبط نموذج VLM مدرب مسبقًا على الروبوتات وبيانات الويب. يعالج النموذج الناتج صور كاميرا الروبوت ويتنبأ بالإجراءات التي يجب أن ينفذها الروبوت.
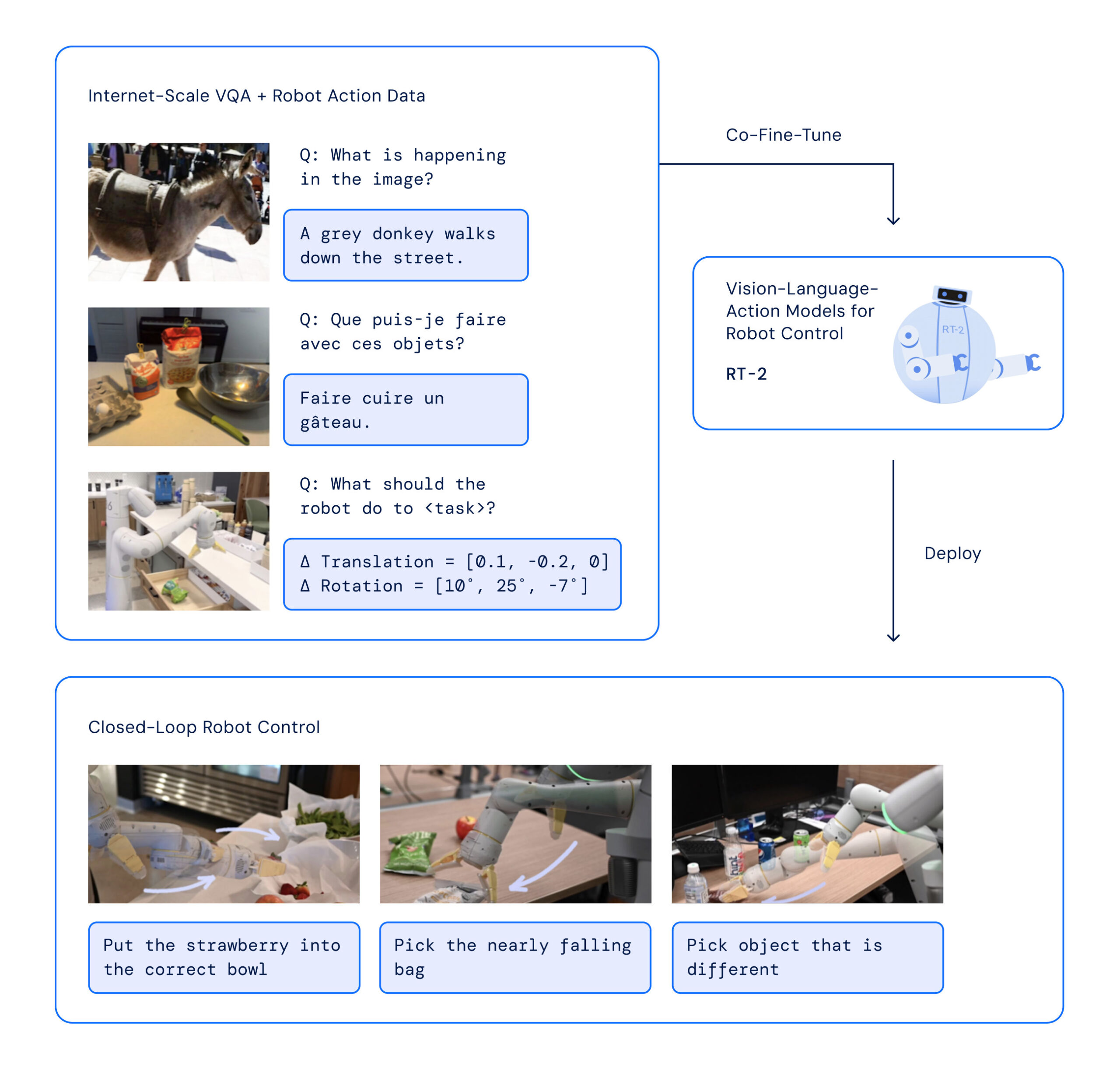{kind=link}
تكبير / قامت Google بضبط نموذج VLM على الروبوتات وبيانات الويب. يأخذ النموذج الناتج صورًا لكاميرا الروبوت ويتوقع الإجراءات التي يجب أن يقوم بها الروبوت.
جوجل
نظرًا لأن RT-2 يستخدم نموذجًا لغويًا لمعالجة المعلومات ، فقد اختارت Google تمثيل الإجراءات كرموز ، والتي تكون عادةً أجزاء من كلمة. “للتحكم في الروبوت ، يجب تدريبه على إخراج الإجراءات ،” Google يكتب. “نتصدى لهذا التحدي من خلال تمثيل الإجراءات كرموز في مخرجات النموذج – على غرار الرموز المميزة للغة – ووصف الإجراءات على أنها سلاسل يمكن معالجتها بواسطة رموز اللغة الطبيعية القياسية.”
في تطوير RT-2 ، استخدم الباحثون نفس طريقة تقسيم أفعال الروبوت إلى أجزاء أصغر كما فعلوا مع الإصدار الأول من الروبوت ، RT-1. اكتشفوا أنه من خلال تحويل هذه الإجراءات إلى سلسلة من الرموز أو الرموز (تمثيل “سلسلة”) ، يمكنهم تعليم الروبوت مهارات جديدة باستخدام نفس نماذج التعلم التي يستخدمونها لمعالجة بيانات الويب.
يستخدم النموذج أيضًا التفكير المتسلسل ، مما يمكّنه من أداء التفكير متعدد المراحل مثل اختيار أداة بديلة (صخرة كمطرقة مرتجلة) أو اختيار أفضل مشروب لشخص متعب (مشروب طاقة).
{kind=link}
تكبير / وفقًا لـ Google ، يمكّن التفكير المتسلسل من نموذج التحكم في الروبوت الذي يؤدي إجراءات معقدة عند توجيهه.
جوجل
تقول Google أنه في أكثر من 6000 تجربة ، تم العثور على RT-2 لأداء المهام السابقة ، RT-1 ، في المهام التي تم تدريبها عليها ، والتي يشار إليها بمهام “المشاهدة”. ومع ذلك ، عند اختباره باستخدام سيناريوهات جديدة “غير مرئية” ، ضاعف RT-2 أداءه تقريبًا إلى 62 بالمائة مقارنة بـ RT-1 بنسبة 32 بالمائة.
على الرغم من أن RT-2 تُظهر قدرة كبيرة على تكييف ما تعلمته مع المواقف الجديدة ، تدرك Google أنها ليست مثالية. في قسم “القيود” من ورقة فنية RT-2، يعترف الباحثون بذلك أثناء تضمين بيانات الويب في المادة التدريبية “يعزز التعميم على المفاهيم الدلالية والمرئية” ، فإنه لا يمنح الروبوت بطريقة سحرية قدرات جديدة لأداء حركات جسدية لم يتعلمها بالفعل من بيانات تدريب الروبوت السابق. بمعنى آخر ، لا يمكنه أداء أفعال لم يمارسها جسديًا من قبل ، لكنه يتحسن في استخدام الإجراءات التي يعرفها بالفعل بطرق جديدة.
في حين أن الهدف النهائي لـ Google DeepMind هو إنشاء روبوتات للأغراض العامة ، فإن الشركة تعلم أنه لا يزال هناك الكثير من العمل البحثي قبل أن يصل إلى هناك. لكن التكنولوجيا مثل RT-2 تبدو خطوة قوية في هذا الاتجاه.